
Amazon AthenaとAWS Glueを使ってHiveテーブルからIcebergテーブルに移行する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データアナリティクス事業本部インテグレーション部機械学習チーム・新納(にいの)です。
Amazon Athenaで利用可能なテーブルフォーマットのひとつであるIcebergでは、ACIDトランザクションやタイムトラベル機能をサポートしたりスキーマ変更に追従できたりと、さまざまな便利な機能が提供されています。UPDATE/DELETE/MERGEといったデータ編集もSQLを経由して行えますので、AthenaとStep Functionsを組み合わせたETLフローも作りやすくなりました。
こうした便利な機能を利用するため、既存のHive形式のテーブルをIcebergに移行したいケースも出てくるかもしれません。
今回はそんなケースを想定していくつか移行方法をご紹介します。
気をつけるポイント
Athenaでは、CREATE TABLE AS SELECT(CTAS)を使ってテーブルを作成する際に一度に作れるパーティションは100件までという制限があります。HIVE、Icebergテーブル両方に同様の制限があります。
制限値を超えてしまうと、Exceeded limit of 100 open writers for partitionsエラーが発生します。
作成したいテーブルのパーティションが100件以下で、Athenaでクエリを完結させたい場合はCTASを利用した移行を、パーティションが100件以上ある場合はGlue Studioで移行する選択肢があります。
パーティションが100件以下
CTASで移行する
CREATE TABLE AS SELECT句を使って、元のHiveテーブルからIcebergテーブルを作成します。WITH句でIcebergの設定をします。
CREATE TABLE <icebergテーブル名> WITH(
table_type = 'ICEBERG',
partitioning = ARRAY [ '<パーティションキー>' ],
location = 's3://<icebergテーブル用のS3バケットパス>',
format = 'parquet',
is_external = false
) AS
SELECT *
FROM <Hiveテーブル名>
今回は検証として、以下のような、yyyy-mm-dd形式のcreate_dateでパーティションが設定されたテーブルを用意しました。update_timeにtimestamp型で日時のデータを持っています。
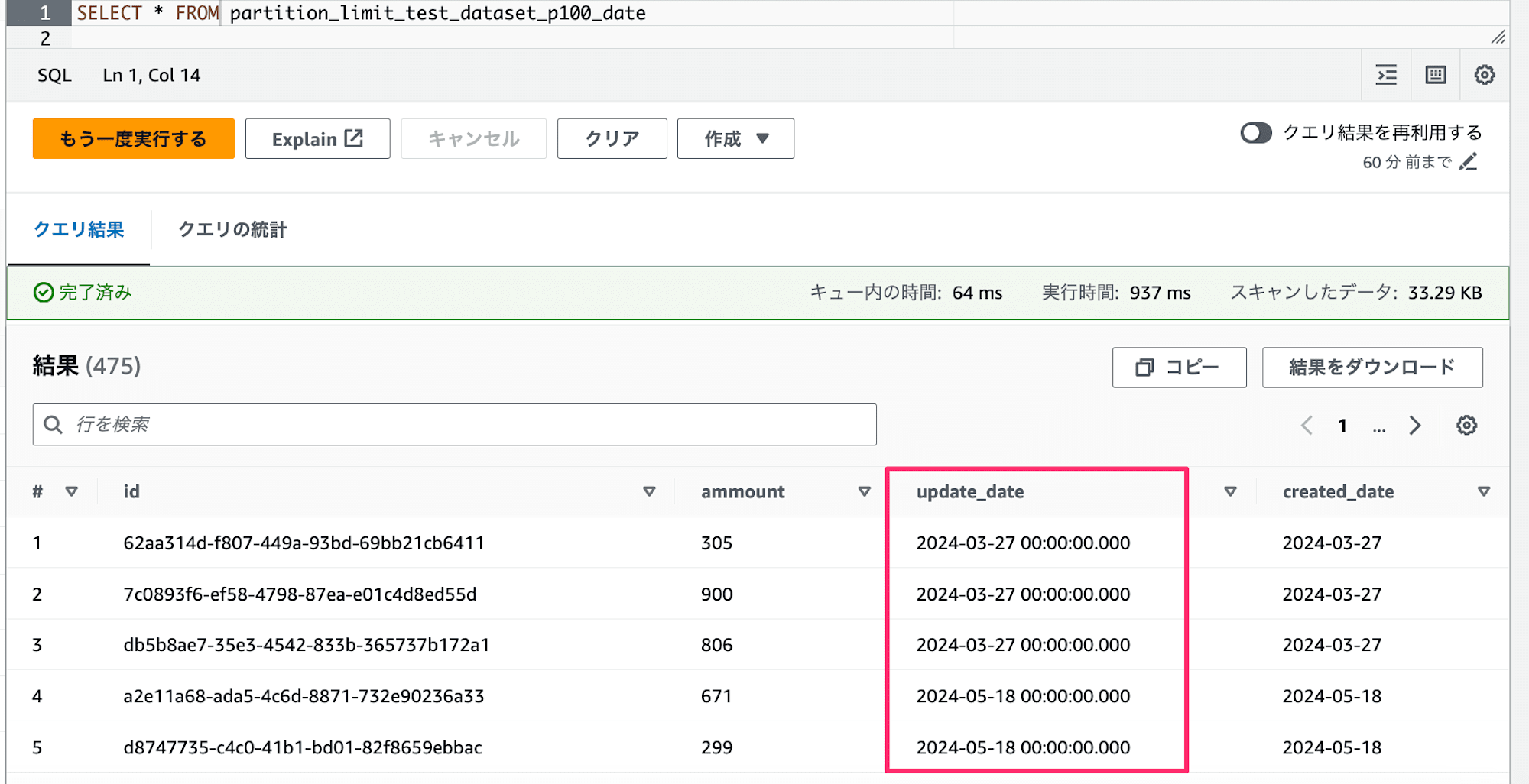
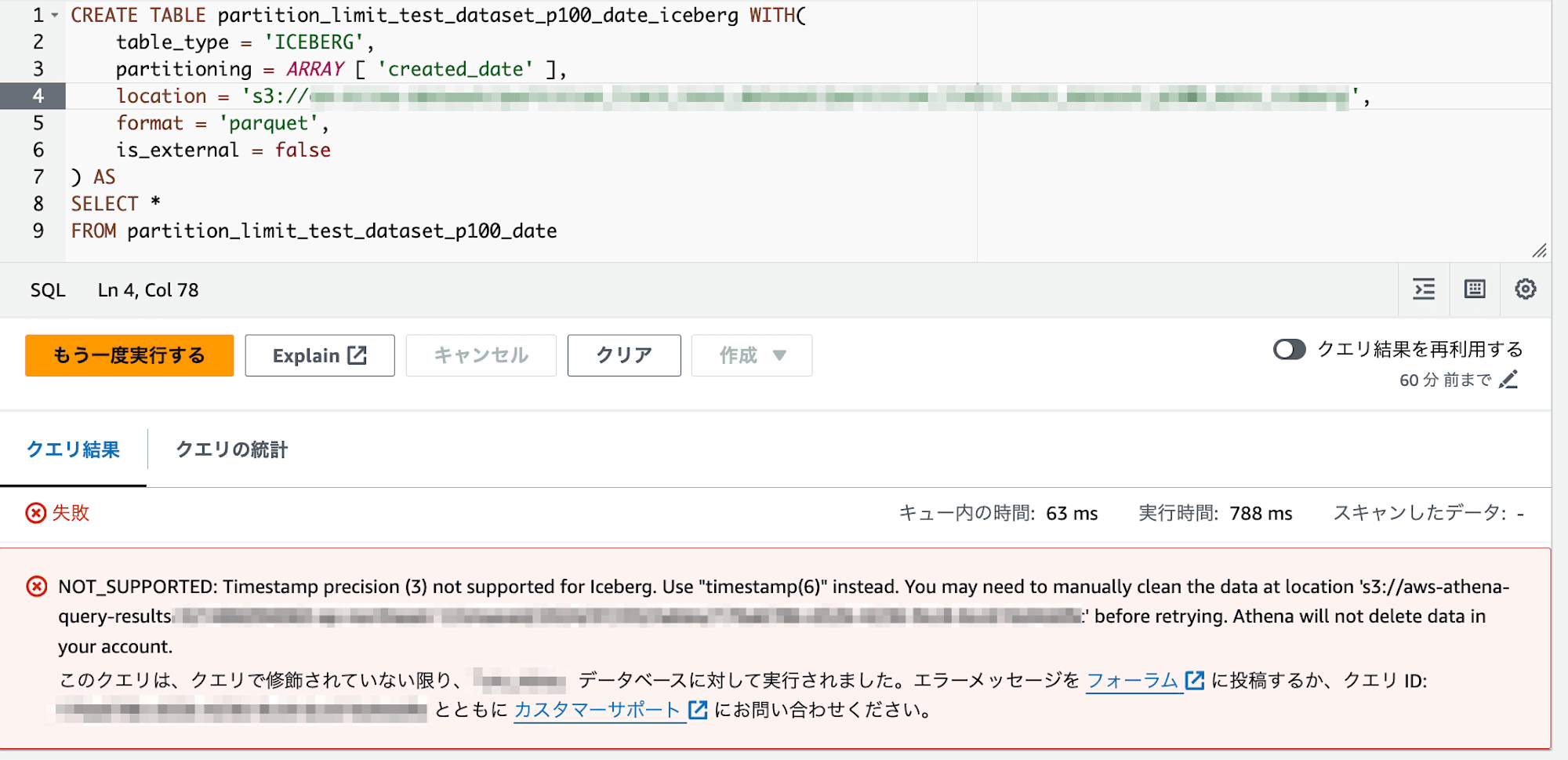
このデータを上記のCTASクエリを元にして実行すると、以下のようなエラーが発生してしまいます。Athenaではtimestamp型はデフォルトで秒の小数点以下3桁まで(ミリ秒単位)の精度を持つtimestamp(3)となりますが、Icebergではこれをサポートしていないために発生するエラーです。
Timestamp precision (3) not supported for Iceberg. Use "timestamp(6)" instead.
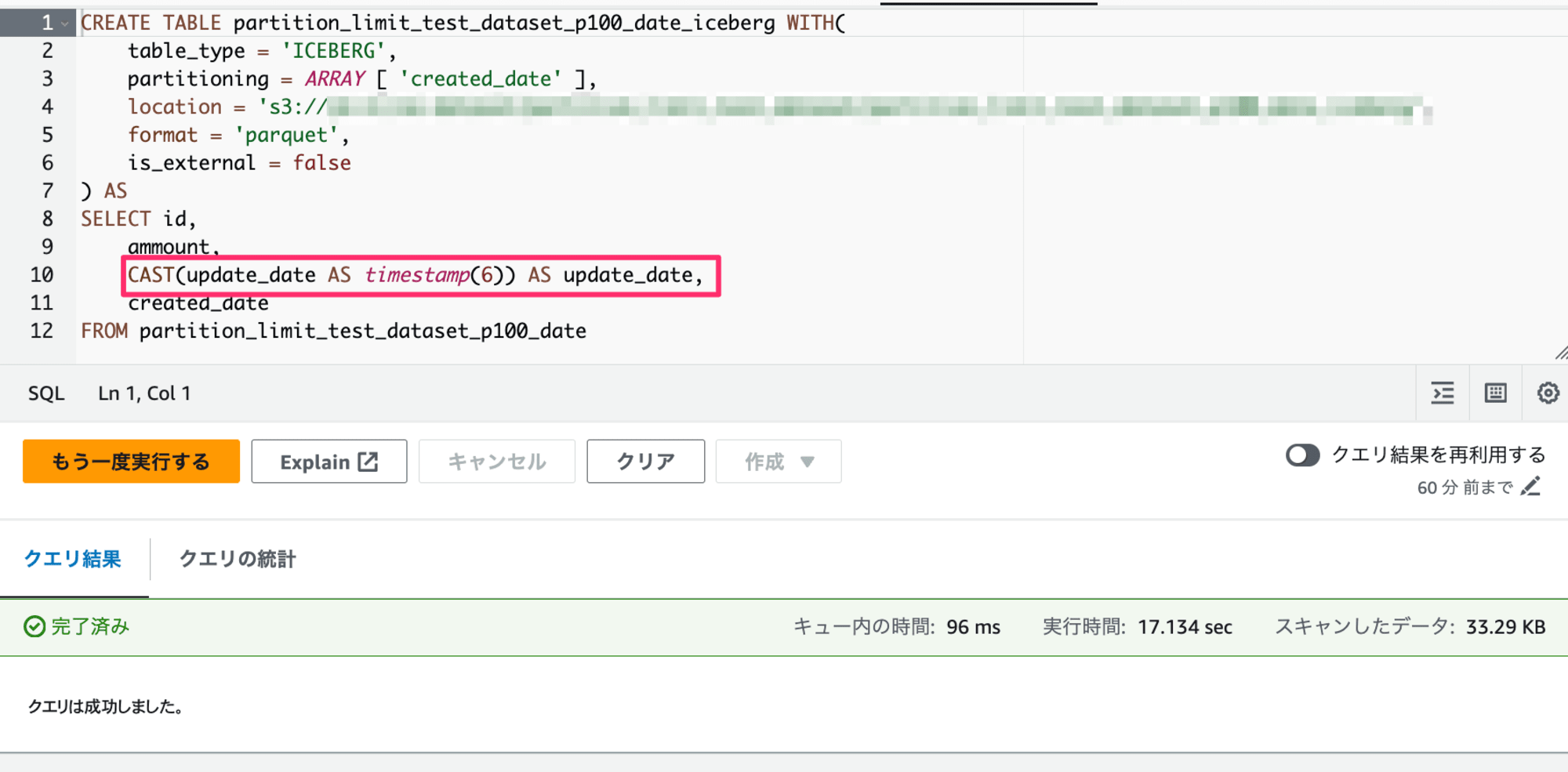
これを回避するにはCTASクエリのSELECT句内でCAST(<timestampのカラム> AS timestamp(6)) AS "カラム名"と記述して秒の小数点以下6桁まで(マイクロ秒単位)の精度のtimestamp(6)にCASTします。ASで別名をつけていないとColumn name not specifiedというエラーが発生しますのでお忘れなく。
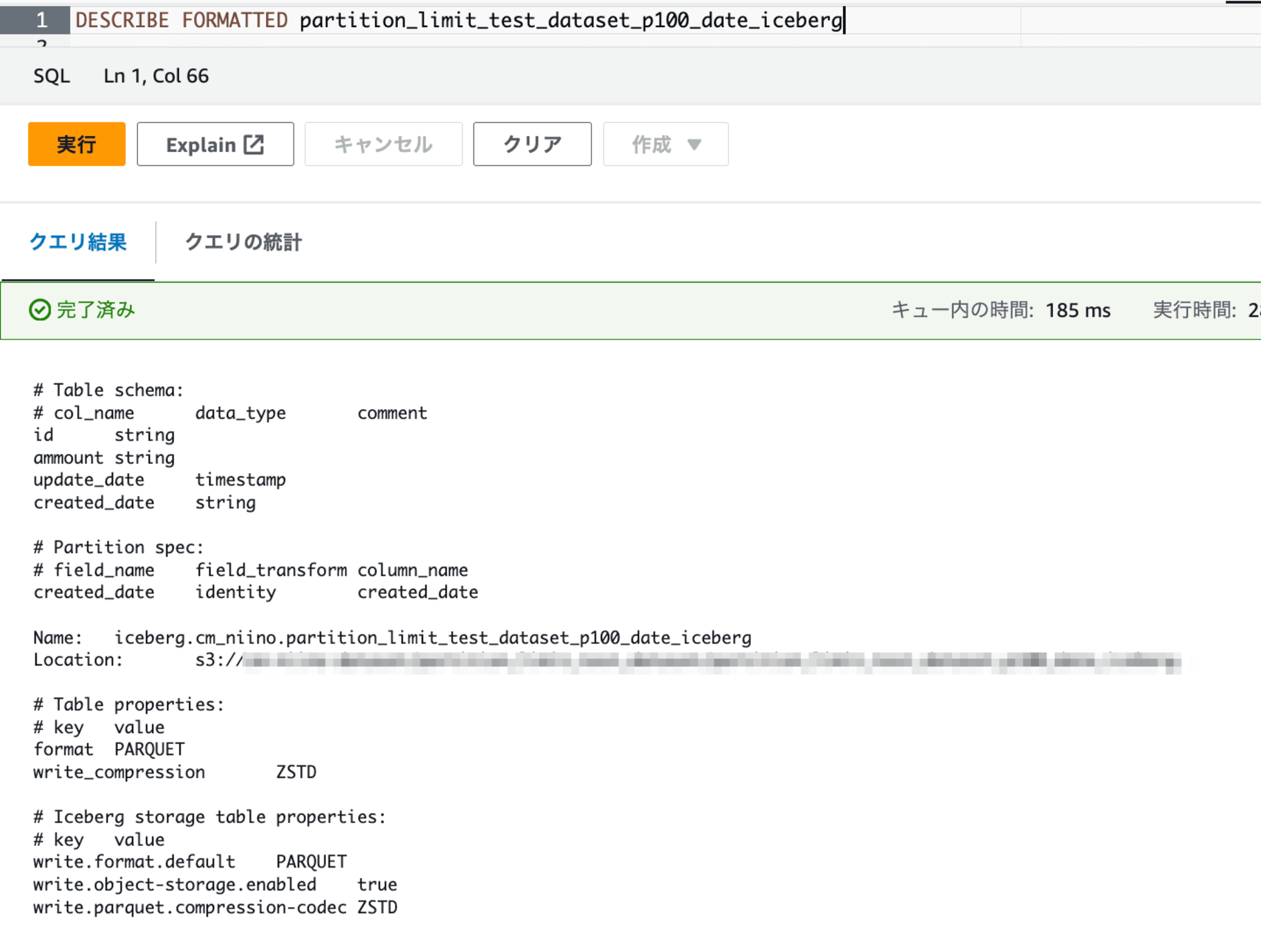
クエリ実行後、DESCRIBE FORMATTED <icebergテーブル名>を実行すると、Icebergとしてテーブルが作成されていることが確認できます。Glue Data Catalogからテーブルを確認することもできますが、DESCRIBEを使うとパーティションキーも一度に確認できます。
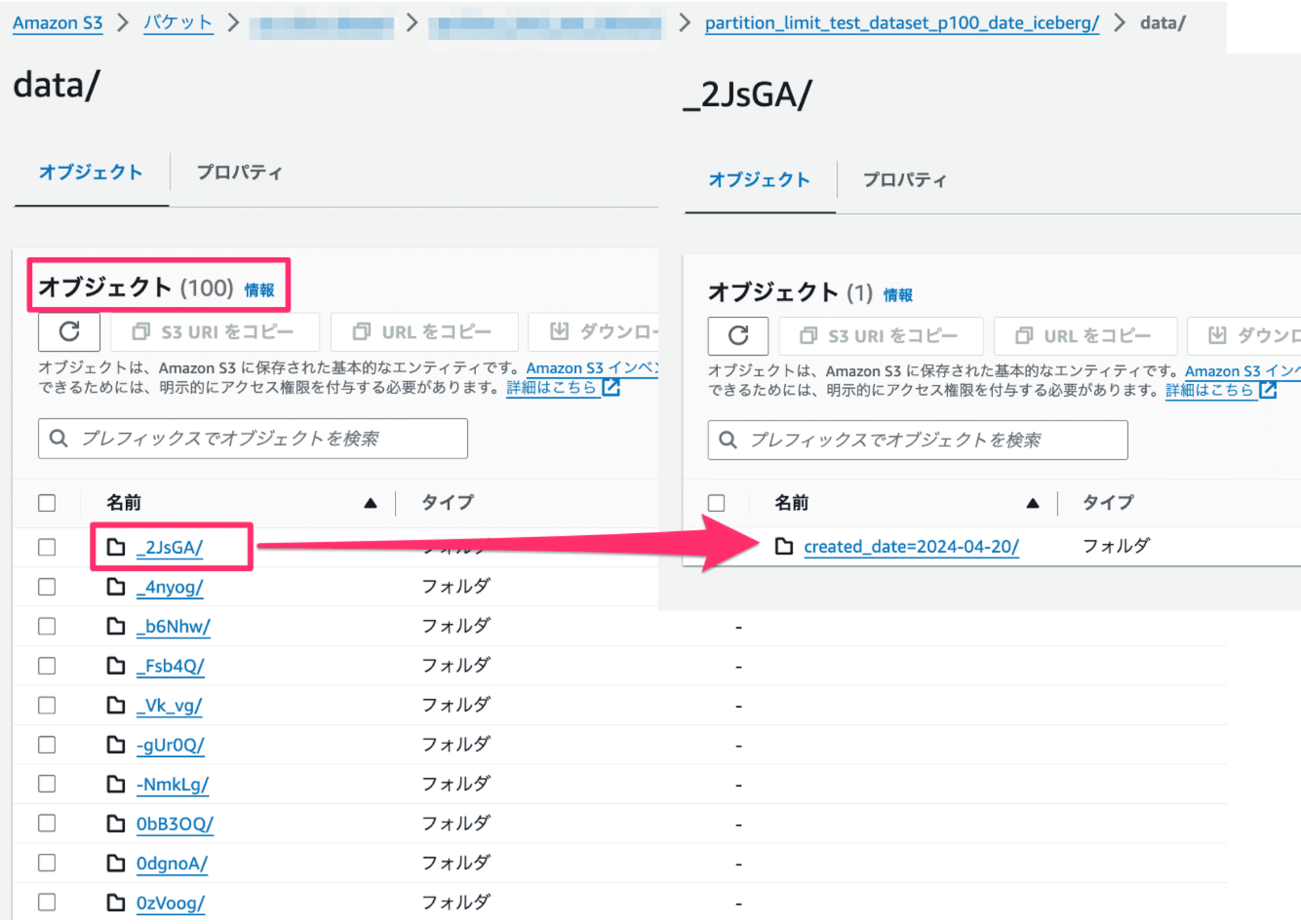
S3バケットを見ると、パーティション100件分のハッシュ化されたフォルダが作成され、それぞれのフォルダ配下にパーティションキーが作成されていることが確認できました。
パーティションが100件以上
Glue Studioで移行する
パーティションが100件以上ある場合は、Glue Studioを使うことで簡単にテーブル移行ができます。
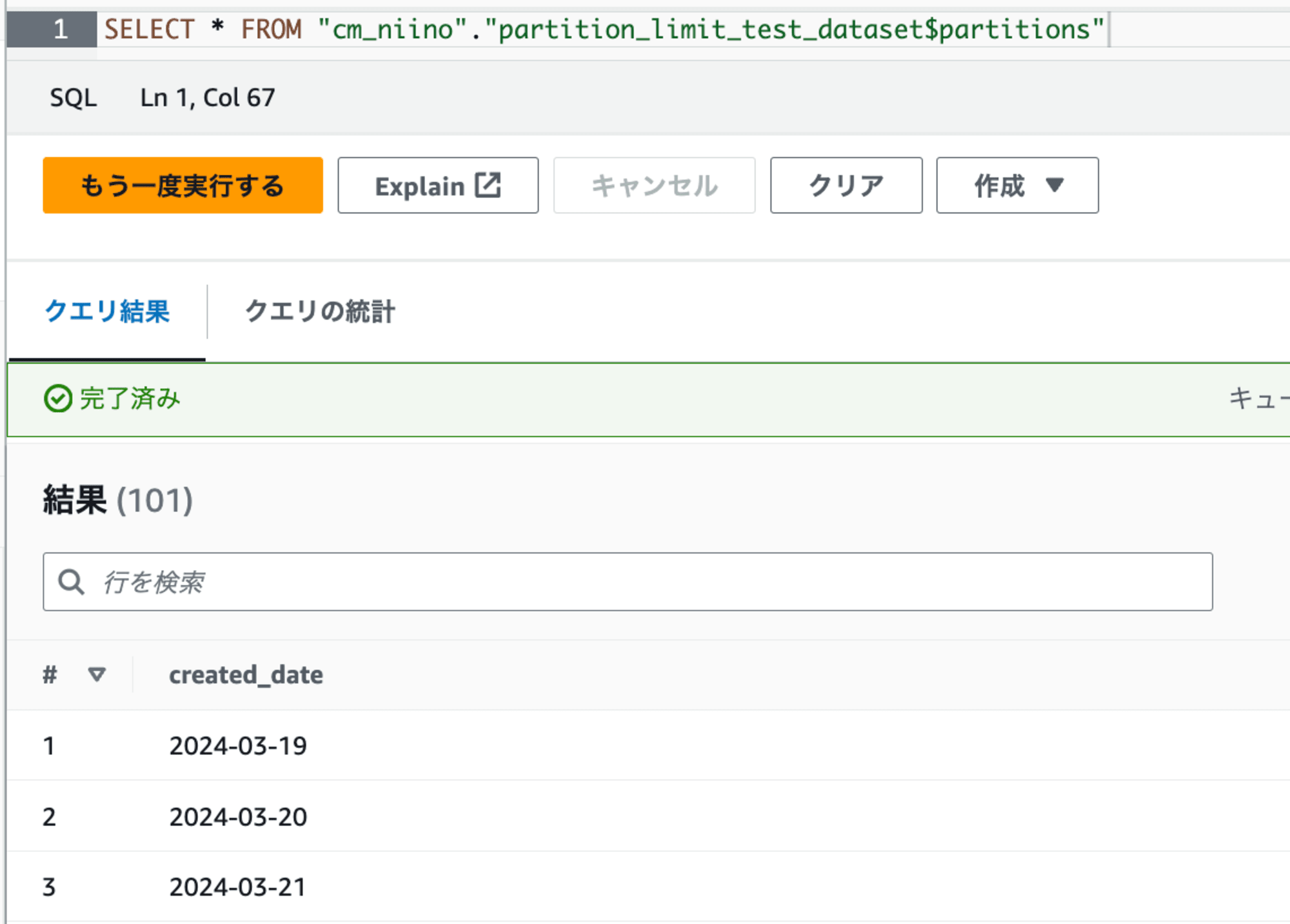
検証のため、以下のとおりパーティションが101件あるHive形式のテーブルを用意しました。
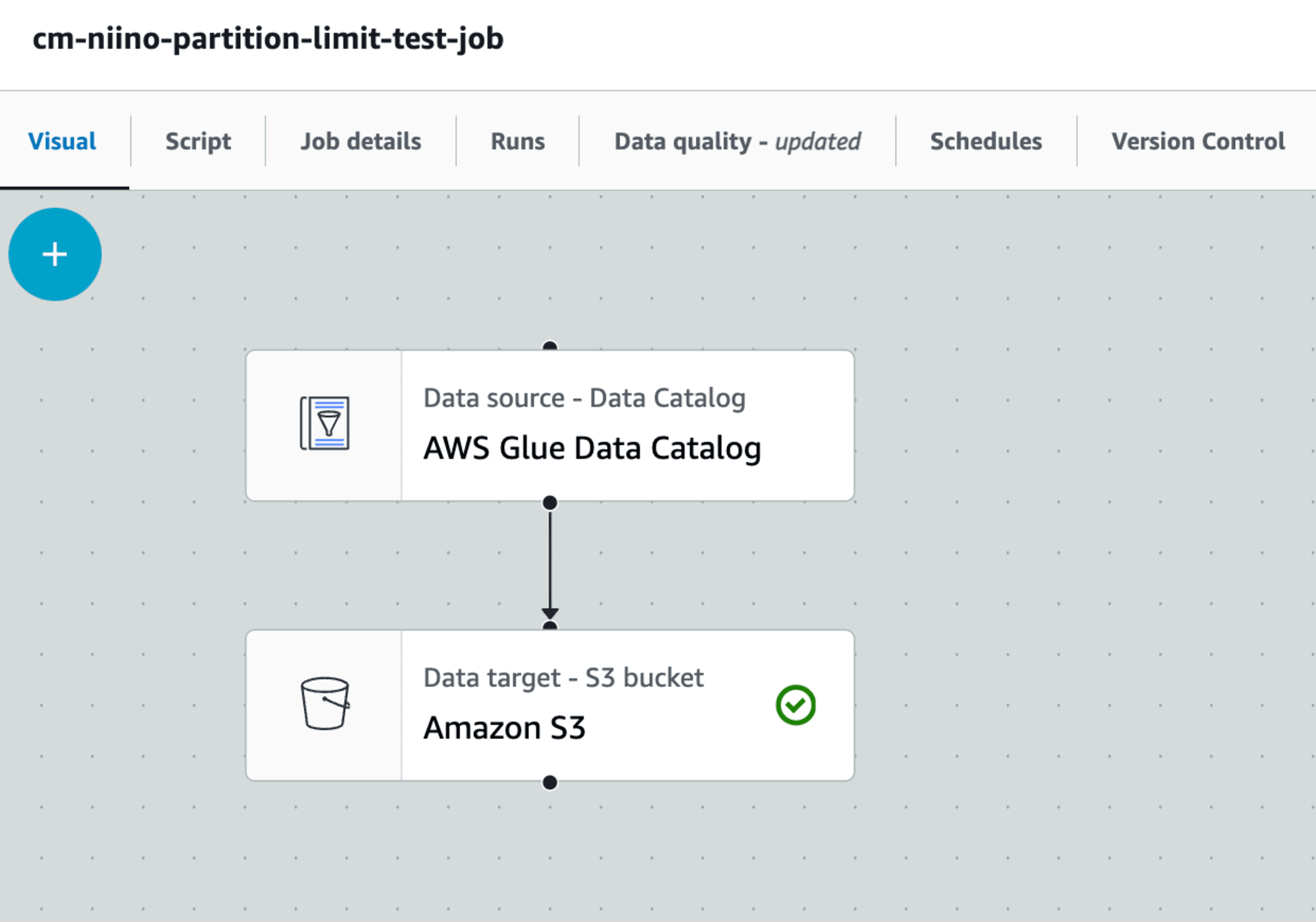
AWSマネジメントコンソールからGlue Studioにアクセスし、Visual Editorから以下のようなジョブを作成します。
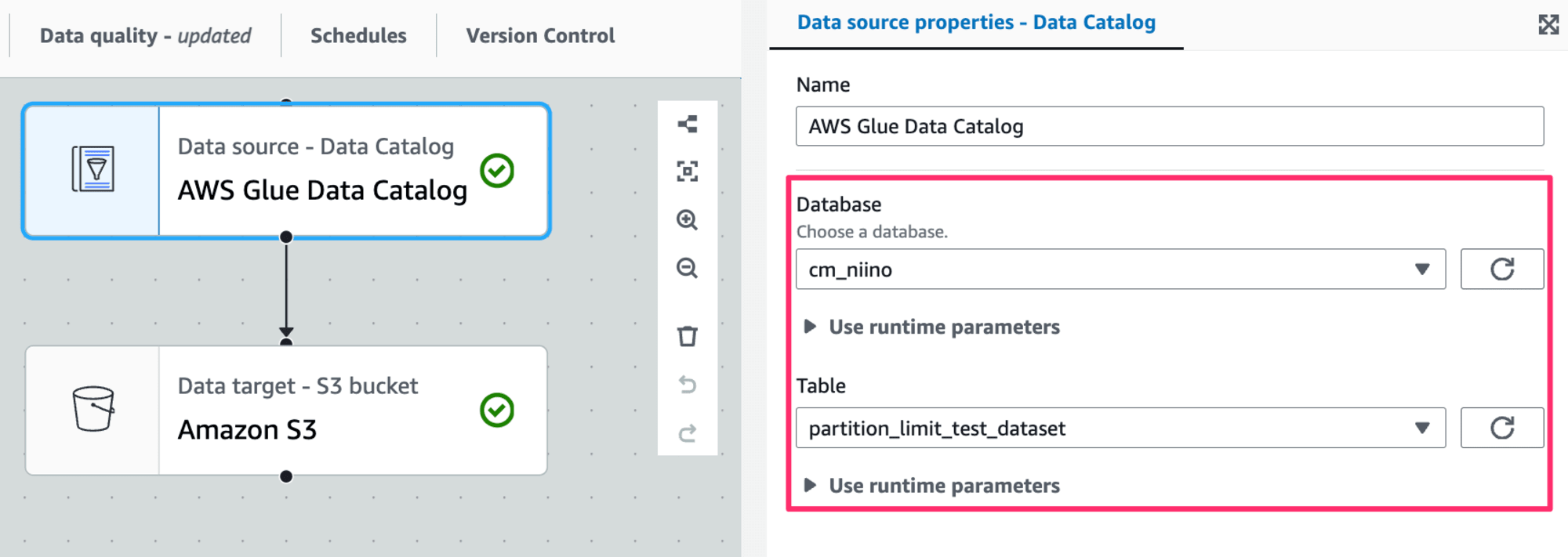
Data SourceにはAWS Glue Data Catalogノードを追加します。Database、Tableにそれぞれ該当するHiveテーブルの情報を指定します。
Data TargetにはAmazon S3ノードを追加します。S3へデータを出力するだけでなく、FormatにIcebergを指定するとCreate a table in the Data Catalog and on subsequent runs, keep existing schema and add new partitionsが有効になり、テーブル作成できます。DatabaseやTableに任意の名前を指定して実行します。
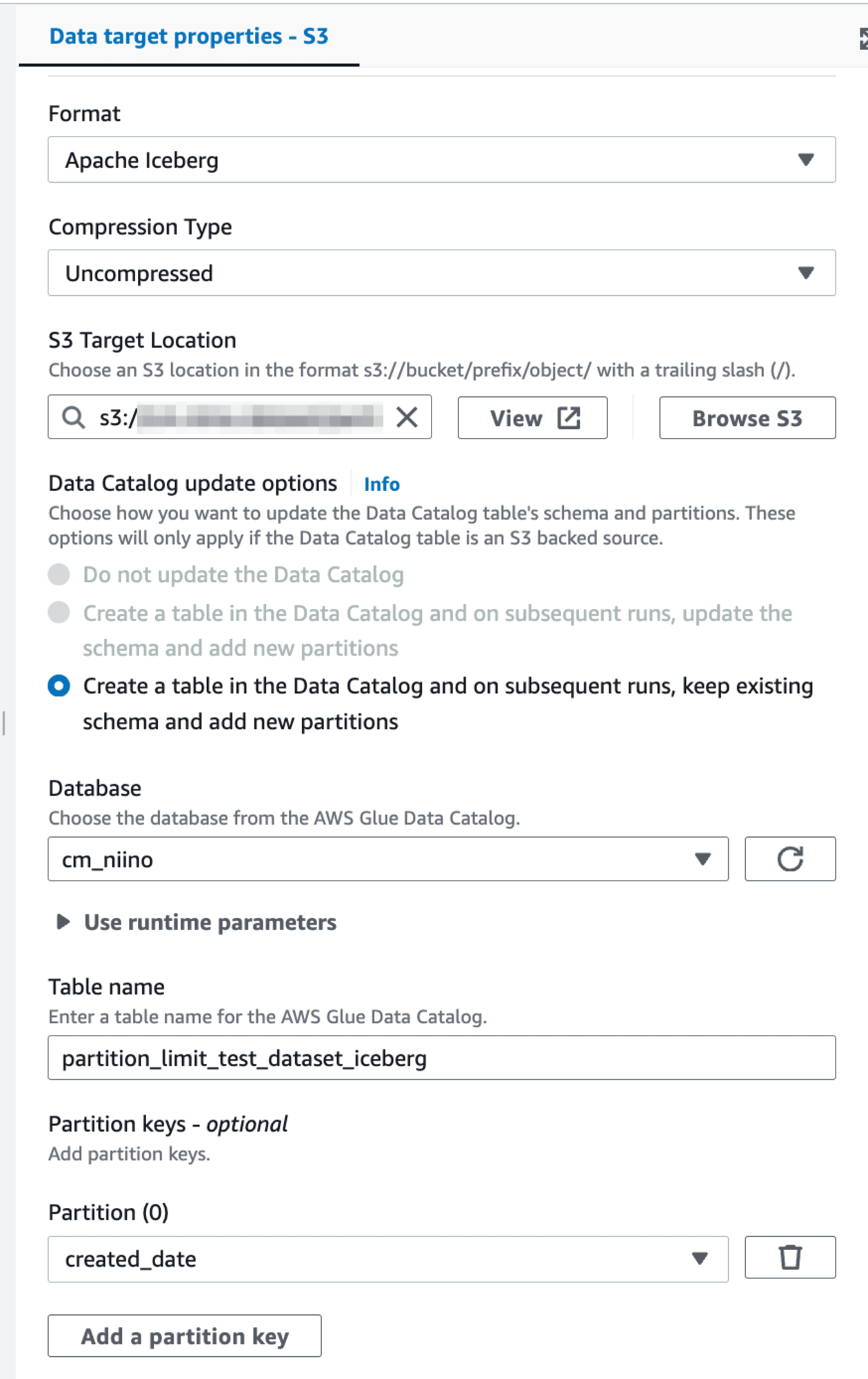
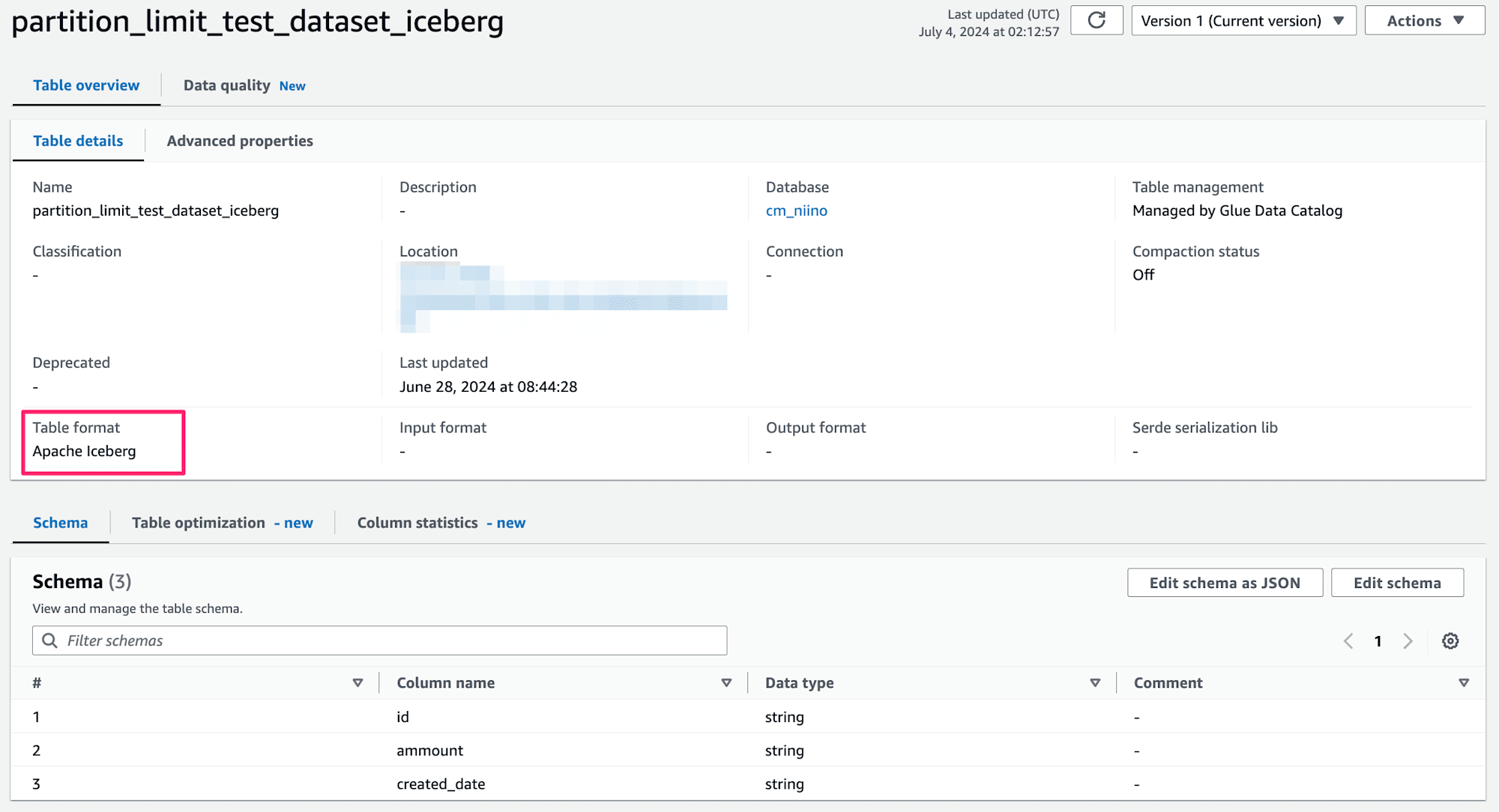
実行後、Glue Data Catalog上でIcebergテーブルが作成されていることが確認できました。もちろんAthenaでも作成されたテーブルを確認可能です。
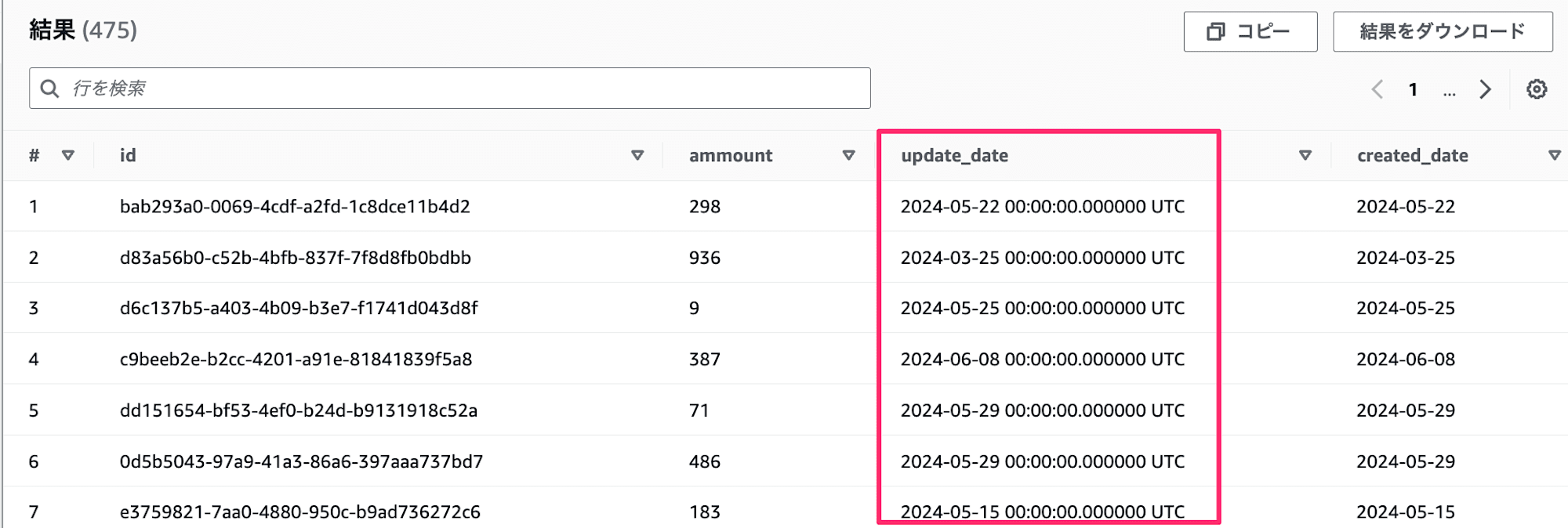
Glueの場合、timestampをCASTしなくてもエラーにならず、タイムゾーン付きのtimestamp(6)でデータが移行されるようです。
さいごに
Hive形式のテーブルをIcebergテーブルに移行する方法をご紹介しました。パーティションが100件以下で、実行をSQLで完結させたい場合はAthena上でCTASクエリを、パーティションが100件以上ある場合はGlue Studioで移行するのがおすすめです。









